

⚡️DeepSeek’s 3FS: The Filesystem Built to Feed Hungry AI Models
💡 Not All Filesystems Are Created Equal—Especially When AI Enters the Chat.


👩💻 Rin: "Obito, I saw something about DeepSeek releasing 3FS, a new filesystem for AI workloads. What makes it special?"
👨💻 Obito: "3FS isn’t your average filesystem. It’s built specifically to handle the unique demands of training large-scale AI models — think multi-petabyte datasets, millions of files, and distributed GPU clusters all needing fast, concurrent access."
👩💻 Rin: "So it’s not just 'another filesystem' — it’s tuned for AI?"
👨💻 Obito: "Exactly. Let’s break down what makes 3FS different."
🚀 3FS vs Traditional Filesystems: What’s the Big Deal?
👨💻 Obito: "Here’s a quick side-by-side so you can see why 3FS stands out."
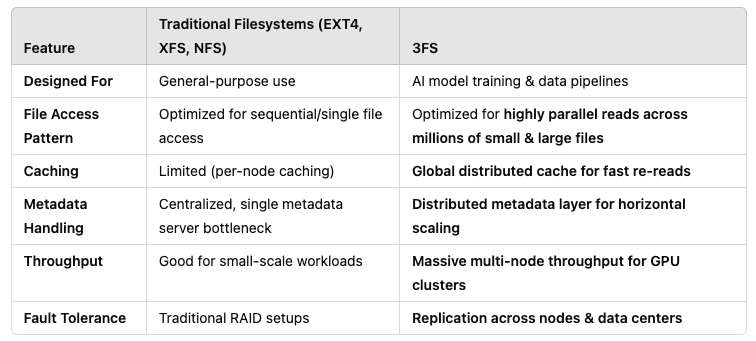
👩💻 Rin: "So 3FS isn’t just faster — it’s fundamentally designed to handle AI workflows."
👨💻 Obito: "Exactly! Standard filesystems choke on millions of small files or concurrent access from hundreds of GPUs. 3FS thrives on it."
🧬 3FS Core Architecture: How It Works
👩💻 Rin: "Okay, but what does 3FS actually do differently under the hood?"
👨💻 Obito: "Let’s break it into layers — because 3FS is all about layered optimization."
1️⃣ Distributed Metadata Service
📂 Traditional filesystems rely on a single metadata server that tracks file locations, sizes, permissions, etc. This becomes a bottleneck.
🔥 3FS spreads metadata across multiple servers, distributing the load — making metadata lookups much faster and more scalable.
2️⃣ Tiered Storage (Hot, Warm, Cold)
🧊 3FS splits data into different ‘tiers’ based on access patterns:
🔥 Hot Data (recent files or frequently accessed training batches) live in fast NVMe caches close to GPUs.
❄️ Warm Data lives in SSD arrays, ideal for files accessed occasionally.
🧊 Cold Data (old logs, unused checkpoints) sits on cheaper HDDs.
👩💻 Rin: "So, frequently used files stay close to GPUs, and the rest gets shuffled off to cheaper disks?"
👨💻 Obito: "Exactly. It’s automatic, so you get the best of both worlds — speed and cost-efficiency."
3️⃣ Global Distributed Cache
🗂️ When GPUs request files, 3FS caches them across multiple nodes, so future reads hit the cache instead of disks.
💥 This is huge for AI training, where the same dataset gets read over and over across different training jobs.
4️⃣ Parallel Data Streaming
🔗 Normal filesystems load files one at a time per process.
⚡️ 3FS splits files into chunks and streams them in parallel across multiple storage nodes.
👩💻 Rin: "So it’s like a download accelerator for training data?"
👨💻 Obito: "Perfect analogy. The more nodes you have, the faster your data loads."
🔬 Example Workflow: Training a Foundation Model with 3FS
👩💻 Rin: "Let’s say I’m training a GPT-like model. How does 3FS help?"
👨💻 Obito: "Here’s the flow:"
1. Trainer requests next training batch (thousands of image/text files)
2. 3FS metadata layer finds all files in parallel across nodes
3. Files are read in parallel from hot cache, warm SSD, or cold HDD
4. Data is streamed directly to GPUs (no unnecessary hops)
5. Frequently used batches stay cached near compute nodes👩💻 Rin: "That sounds way smarter than reading everything sequentially like normal filesystems."
👨💻 Obito: "It’s built for the reality of massive distributed training."
📊 3FS vs Other Distributed Filesystems
👩💻 Rin: "Okay, but how does 3FS stack up against something like Lustre or Ceph?"
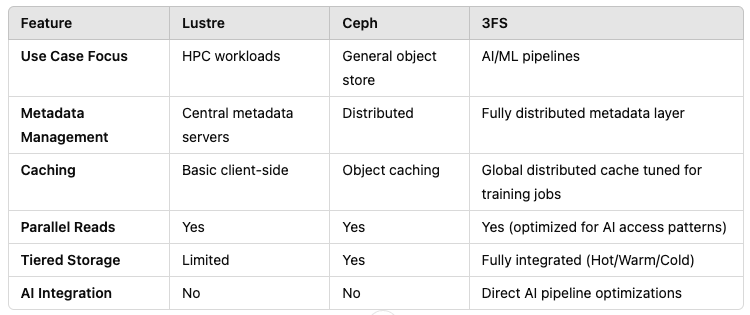
👩💻 Rin: "So it’s more AI-native than Lustre or Ceph?"
👨💻 Obito: "Exactly. Those are great for HPC or general storage — but they weren’t designed specifically for AI training pipelines."
⚠️ Challenges & Considerations
👩💻 Rin: "This all sounds amazing — but what’s the catch?"
👨💻 Obito: "3FS is awesome for training — but like any specialized tool, it has trade-offs."
Potential Challenges
🧰 Operational Overhead: Running a distributed file system with caching, tiering, and metadata sharding isn’t trivial.
💸 Hardware Needs: 3FS shines on clusters with NVMe, SSD, and GPU interconnects — not so much on vanilla cloud instances.
📚 Learning Curve: Teams need to understand AI training data pipelines deeply to optimize 3FS properly.
🚀 Wrapping Up
👩💻 Rin: "Okay, Obito — in one sentence: why should any AI team care about 3FS?"
👨💻 Obito: "Because the faster your data feeds into GPUs, the faster your model trains — and 3FS is purpose-built to keep GPUs fed."
👩💻 Rin: "Sounds like a cheat code for anyone training foundation models or multimodal beasts."
👨💻 Obito: "Bingo — if you’re serious about AI training pipelines, you need to go beyond traditional filesystems."
🔗 Want Us to Dive Deeper?
💬 Should we break down how DeepSeek’s 3FS compares to Databricks’ Unity Catalog or Snowflake Arctic for AI pipelines?
💬 Curious about how 3FS handles multi-tenant training clusters?
Like and Drop a comment — Obito & Rin are always ready for a deep dive!
🚀 Follow BinaryBanter on Substack, Medium | 💻 Learn. Discuss. Banter.